
GENERACIÓN DE UN MODELO CLASIFICATORIO APLICANDO REDES NEURONALES Y COMPARACIÓN CON OTROS ALGORITMOS DE INTELIGENCIA ARTIFICIAL
GENERALIDADES DEL CONJUNTO DE DATOS
El conjunto de datos clasifica las instancias en cuatro (4) clases -atributos de clase- que representan los niveles de aceptación de diferentes tipos de vehículos de acuerdo a los atributos de entrada, la clase tiene cuatro valores:
- unacc: inaccesible o inaceptable
- acc: accesible
- good: bien
- v-good: muy bien
El conjunto de datos está compuesto por 1.728 instancias que se distribuye entre los atributos de la clase de la siguiente forma:
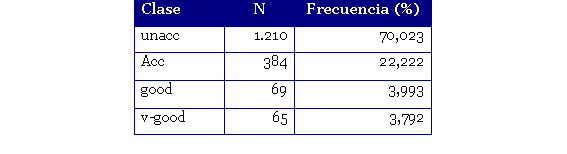
Tabla 1. Frecuencia de las clases del conjunto del dataset
El conjunto de datos se compone, además de 6 atributos nominales de tipo string:
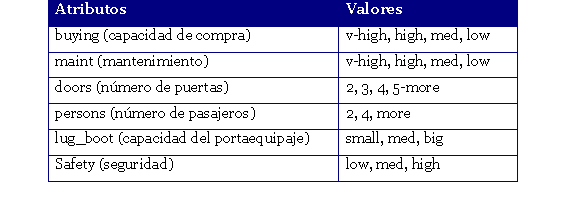
Tabla 2. Atrobutos nominales del dataset
En total existen 21 valores que pueden tomar atributos, el dataset no presenta ningún atributo desconocido o valores perdidos (missing).
GENERALIDADES DE LA SALIDA DE LOS ALGORITMOS DE CLASIFICACIÓN C4.5 (J48), PRISM Y REDES NEURONALES
Para todos los algoritmos aplicados se establece como método de validación la validación cruzada con 10 iteraciones porque se considera que el conjunto de datos no es del tamaño suficiente como para aplicar otros métodos de validación.
Aprendizaje automático a través del algoritmo C4.5 de árboles de decisión
Se realiza un análisis previo de el conjunto de datos observando cuantas instancias se clasifican correctamente entre los modelos de clasificación ID3 y C4.5. El algoritmo ID3 no clasifica todas las instancias mientras que el C4.5 si desarrolla la clasificación de todas las instancias del conjunto de datos.
Se desarrolla el análisis y la validación con los valores de los parámetros de la confianza en un 25% (por defecto) con el fin de que tener un control en la poda del árbol generado, el parámetro binarySplits=False se mantiene en su valor por defecto con el fin de que los nodos no se limiten a bifurcarse en solo dos opciones, para disminuir el error en la poda se establece en “True” el parámetro reducedErrorPruning el cual considera cada nodo del árbol como candidato para la poda, esta técnica elimina las ramas y las convierte en hojas siempre que el árbol no empeore el rendimiento. Previamente se realizó una prueba estableciendo la confianza con un valor de “1,0” y se observa que se mantiene el porcentaje de aciertos por lo que se verifica que el modelo no presenta sobre aprendizaje.
Aprendizaje automático de reglas de clasificación a través del algoritmo Prism
Los cuatro parámetros utilizados por la regla Prism no se modificaron y se dejaron en sus valores por defecto. Se destaca que el valor del parámetro doNotCheckCapabilities se mantiene como “False” dado que no se desea reducir el tiempo de ejecución por lo que las capacidades del clasificador se siguen verificando durante el tiempo de entrenamiento y validación.
Aprendizaje automático usando el algoritmo MultilayerPerceptron
Para este algoritmo se destacan los parámetros de hiddenLayers que se establece en el valor por defecto “a” con el fin de que la capa oculta tenga un número de nodos iguales a la media de los atributos de entrada y de salida, learningRate y momentum se mantienen en su valor por defecto, llama la atención el parámetro decay que cuando se establece en “True” mejora el rendimiento y evita la divergencia del modelo decrementando la tasa de aprendizaje en relación con el número de iteración, otro parámetro que se destaca es el reset que resetea la red con una tasa de aprendizaje menor si la red diverge. Se destaca que el entrenamiento y la validación se realiza con todos los parámetros por defecto dado que así se requiere en la práctica.
ANÁLISIS DE LA SALIDA DEL ALGORITMO MULTILAYER PERCEPTRON
Los nodos 0, 1, 2 y 3 son los nodos de salida del modelo los cuales corresponden a las cuatro clases del conjunto de datos; los nodos 4 al 15 corresponden a los nodos ocultos que en total son 12 dado que se realiza el promedio .
La salida muestra por cada nodo el umbral de excitación calculado para la neurona el cual debe ser superado por la sumatoria ponderada de las entradas, se muestran además los pesos para las uniones del nodo con los demás nodos, en el caso de los nodos de la capa oculta se muestra la misma información, pero además se evidencian los atributos de entrada al nodo. La función de activación utilizada es la función sigmoide que toma el valor de 0,5 -en un rango comprendido entre 0 y 1- cuando no hay entrada indicando la existencia de actividad aún sin ser estimulada la neurona.
VENTAJAS Y DESVENTAJAS DE LOS DIFERENTES ALGORITMOS DE CLASIFICACIÓN
Incluye en el informe: comentarios sobre las ventajas y desventajas de cada algoritmo en lo que se refiere a la representación obtenida del modelo (15% de la puntuación total).

Tabla 3. Algoritmo C4.5
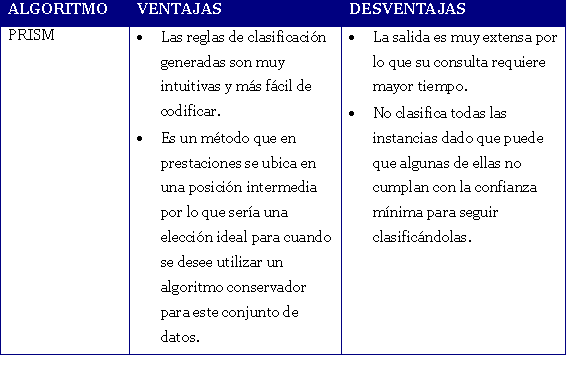
Tabla 4. Algoritmo PRISM
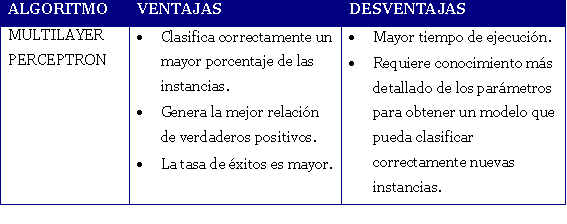
Tabla 5. Algoritmo Multilayer Perceptron
COMPARATIVA ENTRE LOS ALGORITMOS DE CLASIFICACIÓN
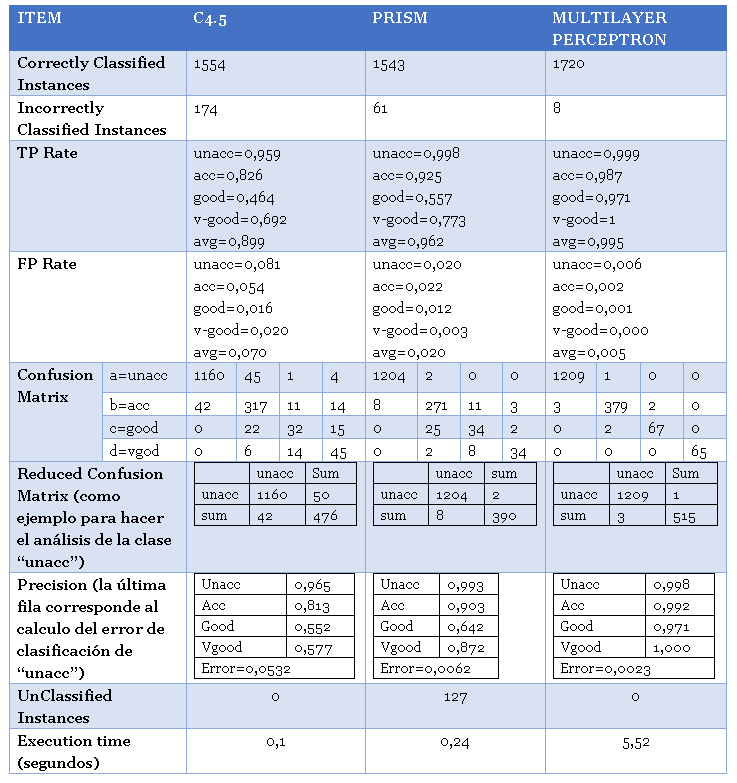
Tabla 6. Comparativa entre los algoritmos de IA
ANÁLISIS DE LOS TIEMPOS DE EJECUCIÓN
Tal como se puede evidenciar en el cuadro anterior los tiempos de ejecución van aumentando entre un algoritmo y otro, un leve incremento se observa entre los algoritmos C4.5 y PRISM, pero es bastante sustancial el incremento en tiempo de ejecución en el algoritmo de redes neuronales a pesar de demorar más tiempo para el entrenamiento y la validación del modelo.
CONCLUSIONES
El desarrollo de los modelos aplicando diferentes algoritmos de clasificación ha permitido evidenciar algunos elementos que se deben tener en cuenta al momento de hacer predicciones sobre un conjunto de datos. En primer lugar, se debe tener en cuenta la cantidad de valores de atributos y clases para decidir cuál es el modelo que mejor desarrolla el entrenamiento y la posterior validación, sin embargo dependiendo de las necesidades del científico de datos se puede elegir un algoritmo a pesar de no desarrollar una clasificación optima, por ejemplo cuando se necesita evidenciar las relaciones de antecedentes y consecuentes, o en casos donde conocer la jerarquía de los datos es vital para analizar un problema o situación.
El algoritmo de redes neuronales clasifica correctamente un mayor número de instancias y por lo tanto el que menos las clasifica incorrectamente. Si se suman los valores de instancias clasificadas incorrectamente de PRISM con el número de instancias no clasificadas este sería el algoritmo con menor desempeño.
La tasa de verdaderos positivos de las clases se incrementa hasta llegar a sus máximos en el algoritmo de redes neuronales, implica que las clases predichas correctas son superiores a las predicciones correctas cuando el valor real es incorrecto; obviamente ocurre lo contrario con la tase de falsos positivos.
La matriz de confusión del algoritmo de redes neuronales evidencia una gran concentración de las instancias en la diagonal lo que indica que en el modelo predominan los verdaderos positivos y los verdaderos negativos, por lo tanto, un mayor porcentaje de las instancias son clasificadas correctamente.
Un análisis más exhaustivo del modelo requerirá que se construya las matrices de confusión reducidas para cada clase, con estas se puede evidenciar el comportamiento de las diferentes tasas para cada clase y se puede dar el caso en que un algoritmo funcione mejor para clasificar una clase específica que el modelo óptimo general. Este análisis permite determinar que para la clase “unacc” el modelo con menor número de errores de clasificación es el de redes neuronales, quizás esta tendencia sea general pero deben evaluarse las matrices de confusión reducidas.
El algoritmo multilayerPerceptron es el que se toma más tiempo para realizar el entrenamiento y la validación posterior (en especial por la validación cruzada) del modelo, pero es el que clasifica más rápido las instancias nuevas.
En general se evidencia que la construcción de modelos observando fenómenos, físicos, biológicos, químicos, etc., tales como las conexiones que se desarrollan en las neuronas de un cerebro humano, pueden dar lugar a modelos que desarrollen mejores predicciones tales como las redes neuronales artificiales o modelos de construcción de árboles más eficientes como el C5.0.
Comentarios